
Migrating to Google Compute Platform – Fit Assessment
In another collaboration with The CTOAdvisor, we have spent some hands-on time with the Google cloud and the process to migrate on-premises applications to the Google cloud. Here on Build Day Live, we will be documenting some of the procedures for that migration. On the CTO Advisor site, we will have more architectural and executive-oriented content around the migration, and you will probably find some of my thoughts on my blog at Demitasse. This is the first post, where we will use the Google Fit tool to examine the CTO Advisor infrastructure and identify possible migration strategies for applications residing on the existing VMware platform that we wish to move to the Google Cloud Platform. If you would prefer to watch a video of this process, you can find that here on the Build Day Live channel. The Fit tool documentation can be found here (Google mFit Documentation) and was the basis for the process outlined here.
The first step is to select or deploy a Linux machine to run the Fit analysis. I chose to deploy a new Ubuntu VM using my template. Once the VM deployed, I logged onto it using PuTTY and a standard userID, not root. The commands to download and make the Fit tool ready to run were taken directly from the documentation:
mkdir m4a
cd m4a
curl -O "https://mfit-release.storage.googleapis.com/$(curl -s https://mfit-release.storage.googleapis.com/latest)/mfit"
chmod +x mfit
Next retrieve inventory information from the vCentre server. These command lines can also be found in the documentation and allow you to fill in your values on the page, which are re-used across commands on the page.
./mfit discover vsphere -I -u [email protected] --url https://ctoadc-vc01.ctoadc.com
You are prompted for the password corresponding to your user ID, make sure this user has sufficient privileges to see the VMs you might migrate. You can see in this example that fifty-six VMs were found.
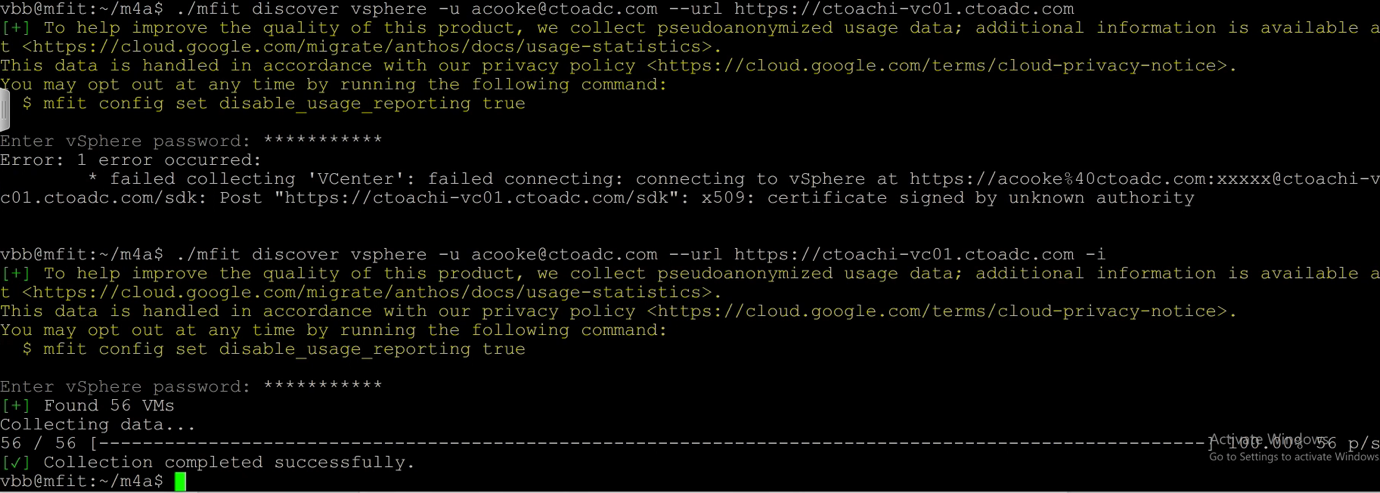
Now we know what VMs we have, and we have the virtual hardware information, we need to retrieve information from inside each VM to identify what application are present and determine what Google services could accommodate the applications. Because all my machines are vSphere VMs, Fit can use the VMTools to run the in-guest discovery. We will need two sets of credentials, one for the vSphere connection just like the previous command, but also one for the in-guest authentication to run discovery inside the VM. The command to discover the VM named graniteweb1 looks like this:
mfit discover vsphere guest --url https://ctoadc-vc01.ctoadc.com -u [email protected] --vm-user vbb graniteweb1 -i
The command prompts separately for the passwords for each purpose, in my case the VM is a Linux machine so the local account is different from the vCentre.

Typing the commands and passwords again and again for each VM we might migrate is a bit tedious, and exactly the type of task that suits automation. I took a simple route and used a shell script and the Linux Expect tool to iterate through a list of VMs and provide the passwords. I used two different Expect scripts. One script for domain-joined Windows machines, which uses the same username and password for vSphere and the guest discovery. One script for Linux hosts uses a different, but standard, username, and password for the guest. My wrapper script retrieves the passwords from environment variables I already set and passes them to the Expect scripts, although they could be hard coded into the script too. Another option is to use some of the Fit scripts that Google has published on GitHub, these use a csv file with credentials for each VM, great if your VMs each have unique credentials.
Wrapper shell script:
#!/bin/bash
for vmname in Dedicated-001 Dedicated-002 Dedicated-003 Dedicated-004 Dedicated-005 Dedicated-006 CTOAHCI-DC01 CTOAHci-VC01-New CTOAHCI-VROPS01 CTOAHCI-VIEWC01 CTOAHCI-VIEWAU01 OGTSS-Prod OGTSS-Test
do
./windows.exp $vmname
done
# Full list granitedb graniteinvoice granitelb granitemaster graniteq1 graniteq2 graniteq3 graniteq4 graniteweb1 graniteweb2
for vmname in granitedb
do
./granite.exp $vmname
done
Windows Expect script:
#!/usr/bin/expect -f set vmname [lindex $argv 0] set windowsPassword [lindex $argv 1] set timeout -1 spawn ./mfit discover vsphere guest --url https://ctoachi-vc01.ctoadc.com -i --dc CTOA-Chicago -u [email protected] --vm-user [email protected] $vmname match_max 100000 expect -exact "\[?25l\[2K\r\[1m\[32m✔\[0m \[1mEnter vSphere password\[0m\[1m:\[0m █\r\[J\[2K\r " send -- "$windowsPassword\r" expect "\[J\[2K\r \[J\[2K\r\[1A\[2K\r\[2K\r\[1m\[32m✔\[0m \[1mEnter vSphere password" send -- "$windowsPassword\r" expect eof Linux Expect script:
#!/usr/bin/expect -f set vmname [lindex $argv 0] set windowsPassword [lindex $argv 1] set linuxPassword [lindex $argv 2] set timeout -1 spawn ./mfit discover vsphere guest --url https://ctoachi-vc01.ctoadc.com -i --dc CTOA-Chicago -u [email protected] --vm-user vbb $vmname match_max 100000 expect -exact "\[?25l\[2K\r\[1m\[32m✔\[0m \[1mEnter vSphere password\[0m\[1m:\[0m █\r\[J\[2K\r " send -- "$windowsPassword\r" expect "\[J\[2K\r \[J\[2K\r\[1A\[2K\r\[2K\r\[1m\[32m✔\[0m \[1mEnter vSphere password" send -- "$linuxPassword\r" expect eof
Running the discovery for about a dozen Windows VMs and a dozen Linux VMs took about half an hour. The Linux discovery is much quicker than the Windows discovery, but as an automated process that you probably don’t run frequently, there is little point in optimizing runtime unless you have thousands of VMs to discover.
There are also Linux and Windows Powershell scripts and SSH-based commands to gather data without using the VMware layer. Whatever tool you use to discover sources, the information is collected to your mFit Linux machine in the hidden ~/.mfit folder. You can then run the analysis against the collected data. I chose to run the assessment for all the possible Google Cloud Platform destinations:
./mfit assess --target-platform all
The assessment process completed almost immediately for my small set of VMs.

The whole point of the process is to generate some reports. The first report is some overview and summary information:
./mfit report --format html > basic.html
You can see the report I generated here; it shows some overview information about the potential to migrate the population of VMs based on the information gathered. This report is for the executive audience who don’t need details. In my case the bottom of the report recommends that ten VMs could be refactored to containers, while 46 should be migrated to Google Compute Engine. Bear in mind that we only retrieved guest configuration information about 26 VMs, so for half the VMs we don’t have enough information to make decisions beyond moving to a new VM platform. 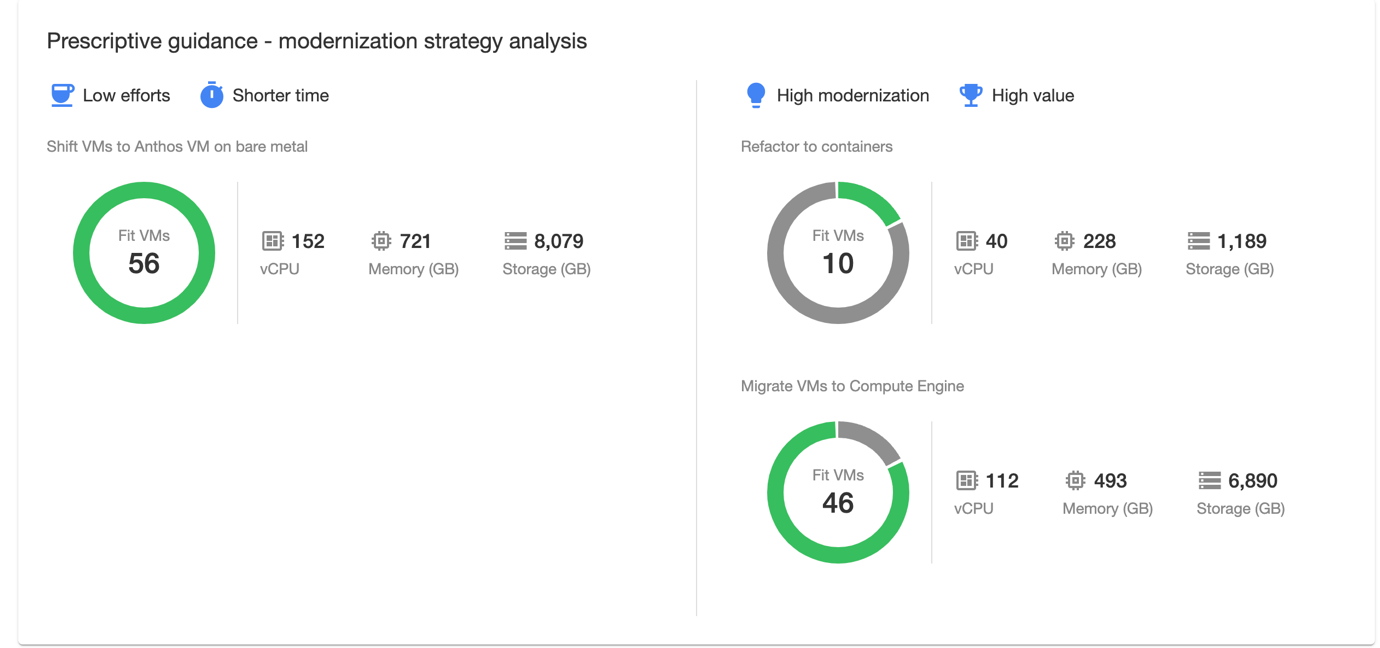
The second report has the details for the engineers that will plan and execute the migration, just add the –full switch to the command:
./mfit report --format html --full > full.html
You can see the full report here. The value of this report is when you dig into each individual system, showing the details of the amount of effort required to migrate to different Google platforms. The machine I will be using in some of the following videos is called obsidian, enter “ob” in the VM Name filter box and take a look at mFit found.
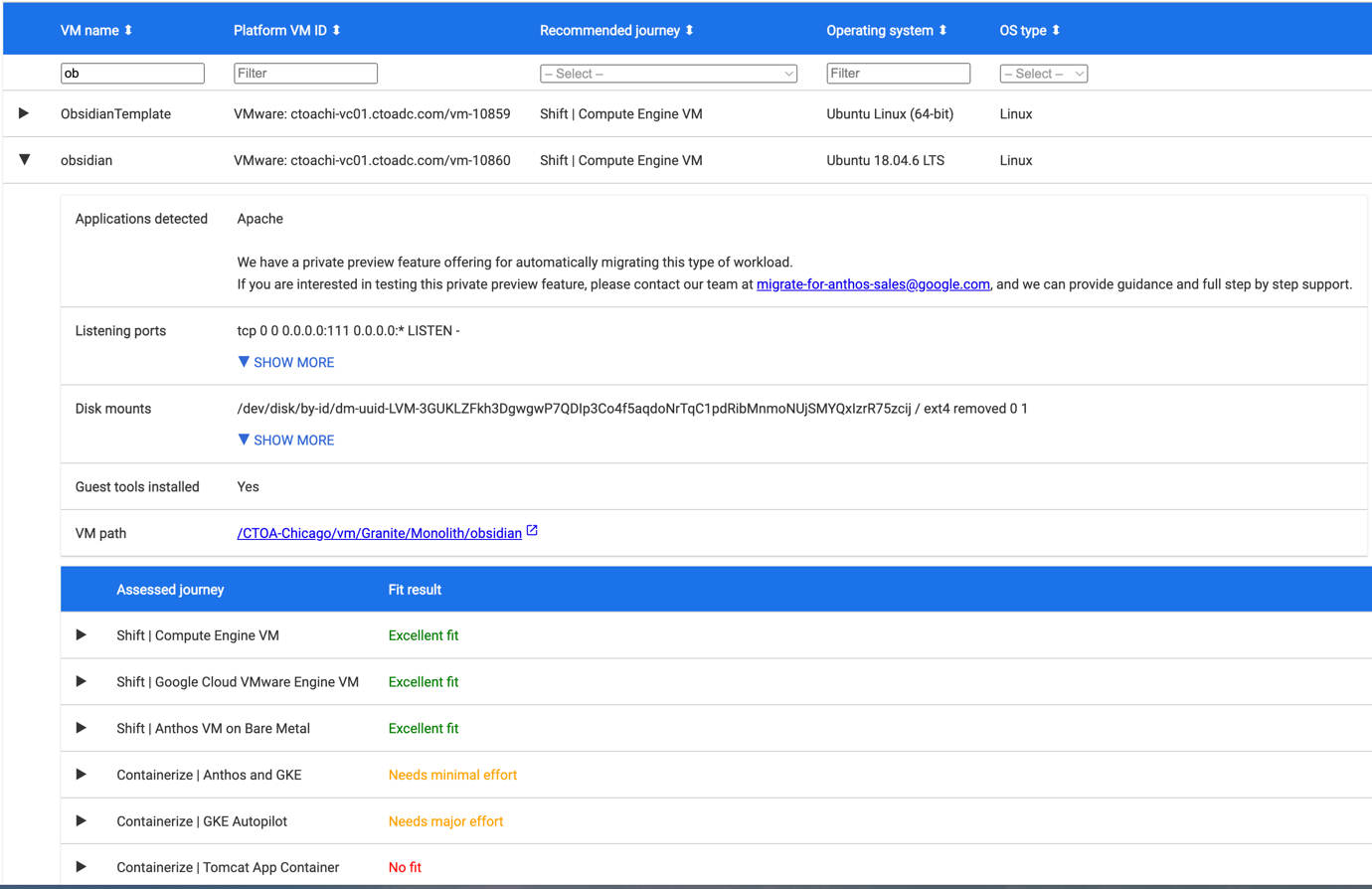
We will migrate this application to the Google Kubernetes Engine (GKE) Autopilot, opening that sub-section shows us what “Needs Major Effort.”
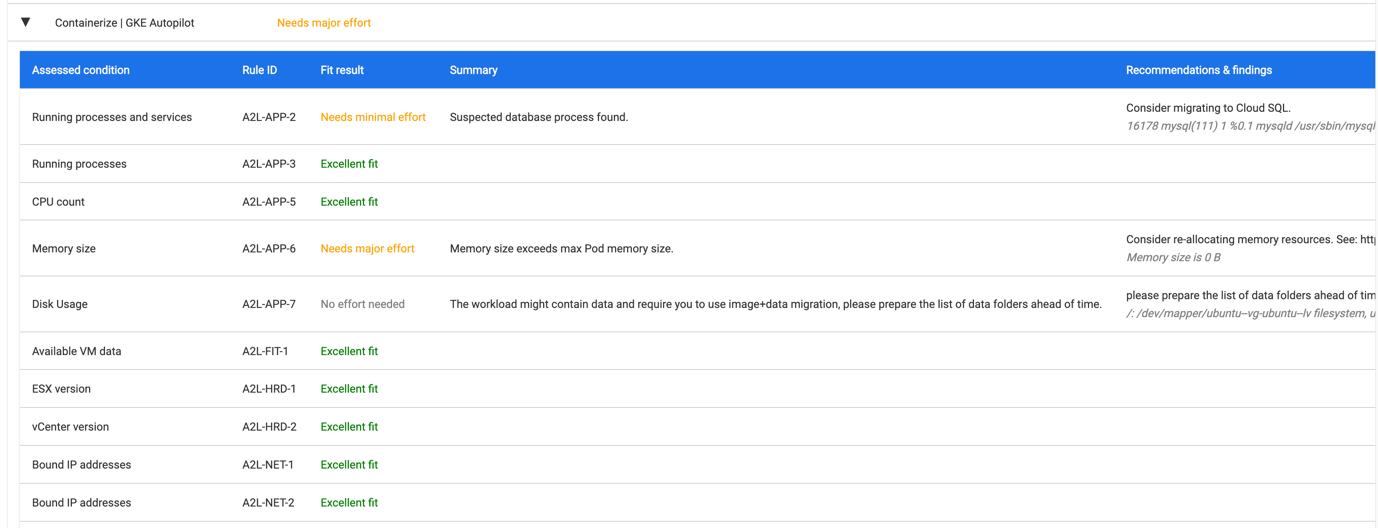
What we find is that there is a database engine (MySQL) running in the VM, which will need to be migrated to a database service before the rest of the application is placed in a container. This migration to CloudSQL is a common part of moving from an on-premises monolithic application to a more cloud-native architecture. The second issue highlighted is that the VM has more allocated RAM than a GKE Autopilot container can be allocated. We will need to see what the performance implications are for reducing the amount of RAM available, migrating the MySQL database to CloudSQL will reduce the RAM requirement.
Also, look at the VM named graniteq2, this is another Linux VM that talks to a remote database (granitedb) and is far easier to re-platform, including migrating to Cloud Run which delivers containers as a service.
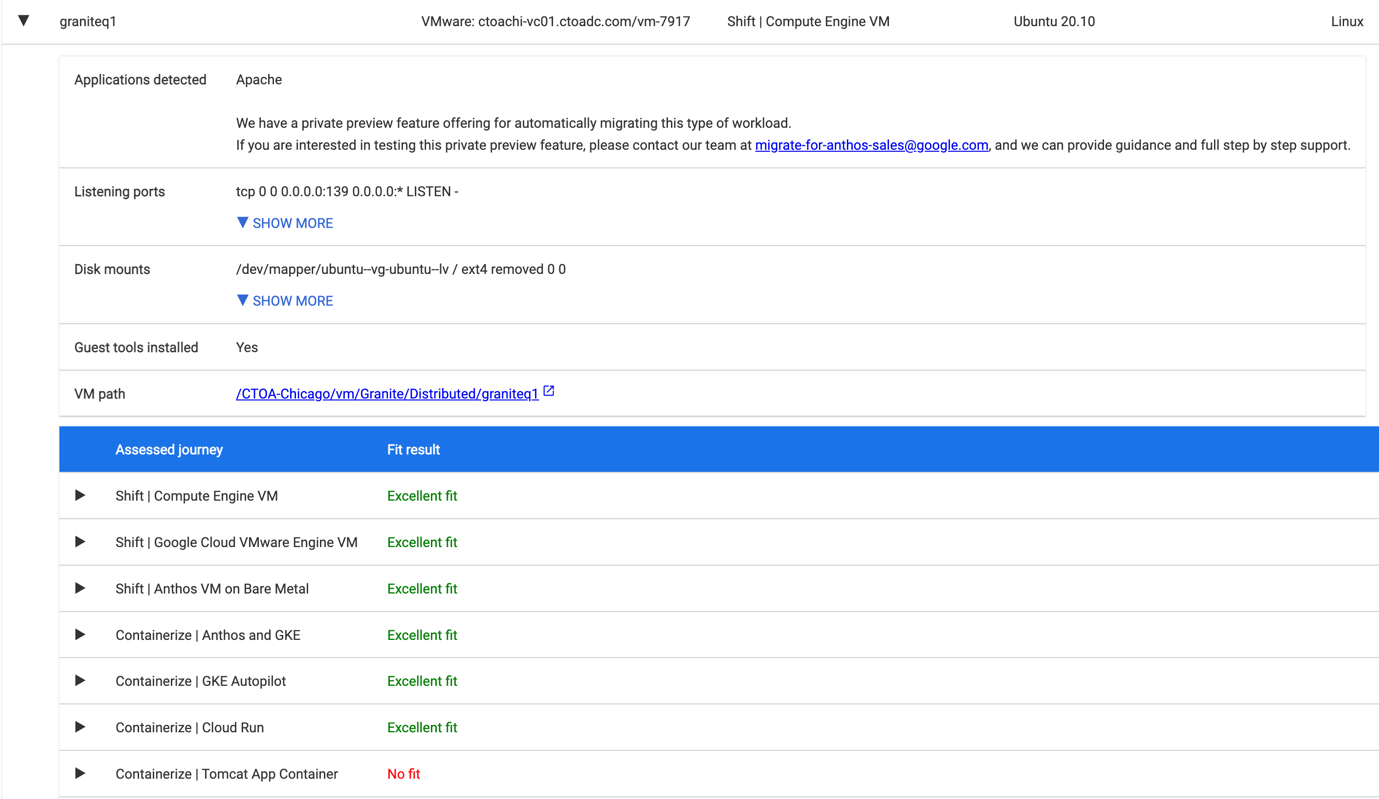
Using this analysis information, we can identify migration candidates and plan the migration methodology for each VM. In the next post and video, we will look at setting up VM replication and testing the migration into a Google Cloud VM.