
![]()
SimpliVity DL380
#HPESimplivity – #BuildDayLive
Build Day Live went to the Americas Solution Center at Hewlett Packard Enterprise in Houston, TC on October 26th, 2017 to learn about and install SimpliVity Hyperconverged 380 into the Build Day Live infrastructure.
About HPE
Hewlett Packard Enterprise is new, but also experienced Enterprise IT company. HPE split from HP to form the new company in 2015. Focusing on Enterprise hardware and services, HPE is all about making your data center run smooth.













Marcel Guerin

Brian Knudtson

Alastair Cook
The Crew
Many people help in the creation of Build Day Live.
These are a few key players you will see in the videos.


Jeffrey Powers
More from HPE SimpliVity
How VM data is managed within HPE SimpliVity clusters, Part 5: Analyzing Cluster Utilization
This is the final blog in a 5-part series on HPE SimpliVity powered by Intel® in which I have explored the architecture at a detailed level to help IT administrators understand VM data storage and management in HPE hyperconverged clusters.
- Part 1 covers how data of a virtual machine is stored and managed within an HPE SimpliVity Cluster
- Part 2 explains how the HPE SimpliVity Intelligent Workload Optimizer (IWO) works, and how it automatically manages VM data in different scenarios
- Part 3 outlines options available for provisioning VMs
- Part 4 covers how the HPE SimpliVity platform automatically manages virtual machines and their associated Data Containers after initial provisioning, as virtual machines grow (or shrink) in size

In this final blog, I will explore some of the scenarios where manual balancing of resources may be required.
As I have done with previous posts in this series, I will just focus on VMware environments for the sake of simplicity. HPE SimpliVity hyperconverged architecture behaves in a comparable manner in either VMware vCenter or Microsoft Hyper-V environments.
Analyzing resource utilization
Intelligent Workload Optimizer and Auto Balancer are not magic wands. They work together to balance existing resources but cannot create resources in an overloaded datacenter, and in some instances manual balancing may be required. I will share some of the more common scenarios, and explore how to analyze resource utilization and manually balance resources within a cluster if required.
Scenario A: Capacity alarms
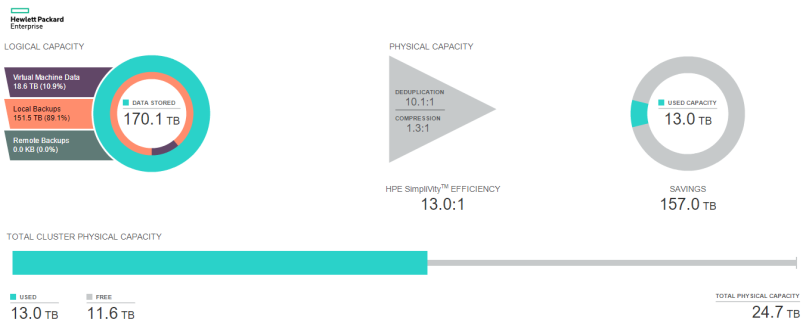
Total physical cluster capacity is calculated and displayed as the aggregate available physical capacity from all nodes within a cluster. HPE SimpliVity does not report on individual node capacity within the vCenter plugin.Total cluster capacity
While overall cluster aggregate capacity may be low, it is possible that an individual node may become space constrained. In this case, vCenter server will trigger an alarm for the node in question.
- If the percentage of occupied capacity is more than 80% and less than 90%, then the Capacity Alarm service will generate a “WARN” alarm
- If the percentage of occupied capacity is more than 90%, then the capacity alarm service will generate an “ERR” event
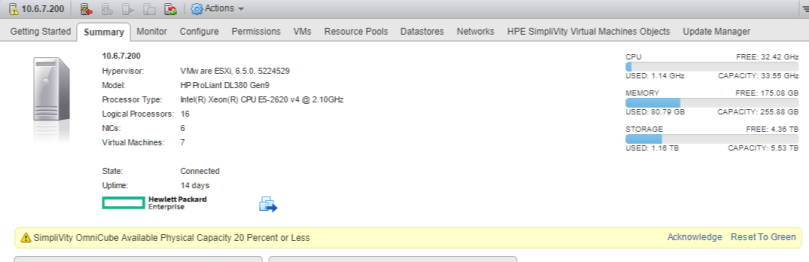
Individual node generating an 80% space utilization alarm
How is it possible for the overall aggregate capacity to remain low within a cluster while an individual node may become space constrained? Take a look at the table below.
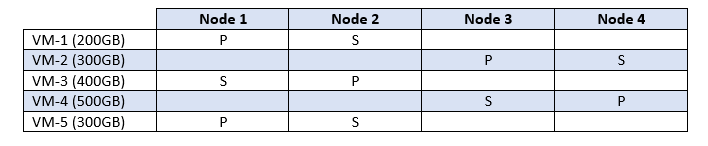
In this simplistic but real-world example, I have assumed physical capacity of 2TB for each node, which includes consumed virtual machine data after deduplication and compression is listed. Therefore, we know the following:
- Total cluster capacity is 8TB (2TB per node X 4 nodes)
- Currently, cluster space consumption 3.4TB
- IWO balancing service has distributed the load/storage consumption evenly across the cluster
- Total cluster consumption is 42.5% (I’ll spare you the math!)
If any one node exceeds 1.6TB utilization in this scenario, an 80% capacity alarm will be triggered for that node.
If I were to add more virtual machines to this scenario or grow existing virtual machine sizes, that would trigger 80% and 90% utilization alarms for two nodes within this cluster, as consumed on-disk space will scale linearly for both nodes that contain the associated primary and secondary data containers. However, in the real world, things can be slightly more nuanced for a number of reasons.
- Odd number clusters may not scale linearly in every scenario. One node in the cluster will be forced to house more primary and secondary copies of virtual machine data, which may trigger a capacity alarm
- As backups grow or shrink in size and eventually timeout, different nodes can experience different utilization levels
- VMs will have backups of various sizes associated with them (stored on the same nodes as the primary and secondary data containers for deduplication efficiency), along with backups of VMs from other clusters (remote backups)
- VMs with highly unique data which does not deduplicate well, might not scale linearly
Scenario B: Node and VM utilization

Use the dsv-balance-show with the –-showHiveName –consumption –showNodeIp arguments to view individual node capacity and virtual machine consumption. This command can be issued from any node within the cluster.
Output from dsv-balance-show command indicates:
- Used and remaining space per node
- On-disk consumed space of each VM
- Consumed I/O of each node and VM (Note: this is only a point-in-time snapshot of the node/VMs when the command was issued)
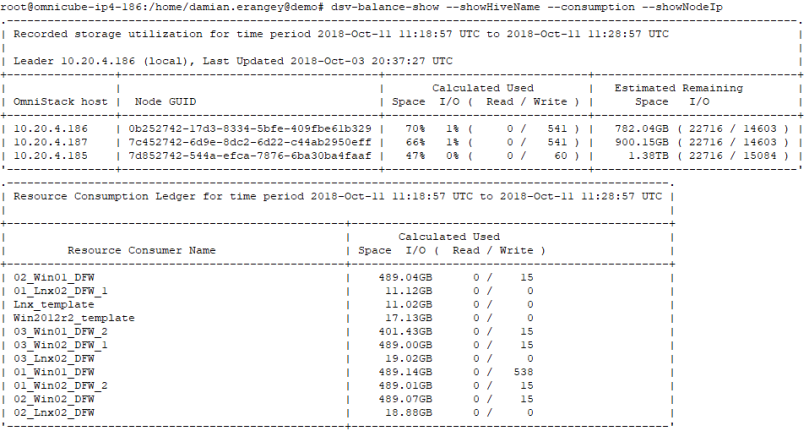
Output from dsv-balance-show command
Scenario C: Viewing virtual machine data container placement
In the event of an 80% or 90% node utilization warning, the distribution of virtual machine data across the cluster can be viewed with the dsv-balance-manual command. This is a powerful tool and can be used to accomplish several tasks.
- Gather current guest virtual machine data including data container node residence, ownership, and IOPS statistics
- Gather backup information for each VM (number of backups)
- Provide the ability to manually migrate data containers and(or) backups from one node to another
- Provide the ability to evacuate all data from a node to other nodes within the cluster automatically
- Re-align backups that may have become scattered
The dsv-balance-manual command displays the output to the screen (you will have to scroll back up on your ssh session!) and creates an analogous .csv ‘distribution’ file named: /tmp/replica_distribution_file.csv.
If invoked with the –csvfile argument, the script executes the commands to effect any changes made to the .csv file (more on that later).
I will explore each functionality.
Listing data container node locations, ownership, on-disk consumed size and current IOPS statistics
Issuing the command dsv-balance-manual without any arguments is shown below. After the command is issued you will be prompted to select the required datacenter/cluster you wish to query. The following information is outputted directly to the console.
- VM ID (used for CSV file tracking)
- Owner (which node is currently running the VM)
- Node columns (whether the node listed contains a primary or secondary data container for the VM)
- IO-R (VM read IOPS)
- IO-W (VM write IOPS)
- SZ(G) (on-disk consumed size of the VM – logical)
Logical size is essentially the size consumed by the VM OS – this value does not take deduplication and compression into account. - Name (VM name)
- IOPS R (aggregate node read IOPS)
- IOPS W (aggregate node write IOPS)
- Size G (total consumed on-disk space – logical)
This value represents the sum logical size of each data container on the node and the local/remote backup consumption. However only on-disk VM-size is broken out in the SZ(G) column. You can also use dsv-balance-manual -q to query sum total logical backup sizes. - AVAIL G (total remaining physical node space)
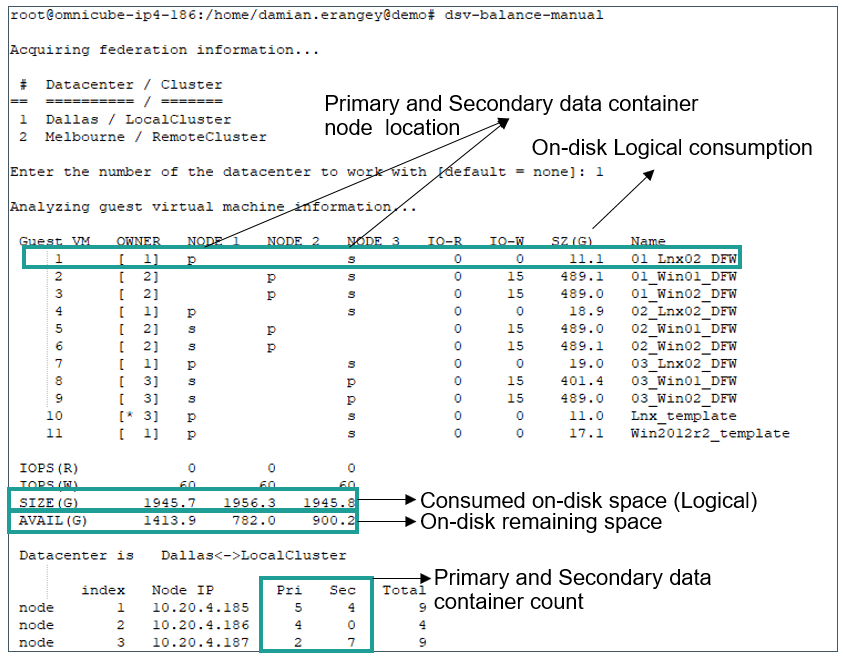
Output of dsv-balance-manual command
Taking action
As stated above, the dsv-balance-manual command provides the ability to manually migrate data containers and/or backups from one node to another if required. While straightforward, it is advisable to contact HPE technical support for assistance with this task (at least initially until you become comfortable with its execution). You can also follow the Knowledge Base instructions (KBs) available within the HPE Support Center.
The command mainly lists logical information apart from AVAIL (G) (physical value). Before migrating a particular data container to another node, it may be useful to understand the physical size of the data container (unique VM size). Again, HPE technical support or KB documentation can assist with calculations before any such migration may be executed.
It’s all about management options
By now you can see that HPE SimpliVity offers a plethora of options for managing virtual machine data. Although I have only skimmed the surface with this technical blog series, many of the functions are intuitive and easy to follow if you have experience with VMware vCenter or Microsoft Hyper-V interfaces.
If you need assistance with the more sophisticated features, or if you just want to dig a little deeper into the technology, visit https://support.hpe.com/hpesc/public/home
More information about the HPE SimpliVity hyperconverged platform is available in these technical whitepapers:
- HPE SimpliVity Data Virtualization Platform provides a high level overview of the architecture
- You’ll find a detailed description of HPE SimpliVity features such as IWO in HPE SimpliVity Hyperconverged Infrastructure for VMware vSphere and HPE SimpliVity Hyperconverged Infrastructure for Microsoft Hyper-V
Fortify and streamline your virtualized infrastructure with hyperconvergence
In 2019, many of the pressing IT concerns of the previous year have been amplified, and several new challenges have been added to the list. Organizations across the world are challenged by crucial upgrade requirements due to hitting peak capacity of storage systems or facing end-of-life support from the vendor. This dilemma is compounded by growing expenses and resources needed to assist in managing, configuring or optimizing storage, or verifying backups. Then there is the booming number of diverse VDI users to cater to. For many of these organizations, traditional IT is not the best choice for their modern workloads. Known for its complex and expensive nature, traditional infrastructure is not really innovation-centric and it cannot accommodate resources for work on strategic projects.
Examining the shift toward hyperconvergence
The need of the hour is reliable storage efficiency and prompt backups. Hence, IT teams are scouting for infrastructure that boosts agility within the data center while enhancing resource optimization. This need has led to a global shift toward adoption of converged and hyperconverged solutions.
For enterprises trying to gain cloud-like agility without compromising performance or protection, hyperconverged solutions like HPE SimpliVity offer immense benefits. HPE SimpliVity powered by Intel® removes multiple IT complexities by consolidating all hyperconverged infrastructure and advanced data services for virtualized workloads into each hyperconverged node. Owing to benefits being offered to diverse enterprises, HPE was recently recognized by Gartner in the 2018 Critical Capabilities for Hyperconverged Infrastructure, and by customers in the Gartner Peer Insights Customers’ Choice award.
Key features of HPE SimpliVity infrastructure
A few key features demarcate the award-winning HPE SimpliVity as a radical improvement as compared to early forms of convergence and hyperconvergence. HPE SimpliVity Data Virtualization Platform, the hyper-efficient data architecture underlying the solution, deduplicates, compresses, and optimizes all data at inception without affecting performance. HPE SimpliVity 380models are available on the HPE ProLiant DL380 server platform (VMware or Hyper-V enabled). The HPE SimpliVity 2600, based on the Apollo server platform, has been optimized for environments that require higher density nodes. A TechValidate survey of existing HPE SimpliVity customers revealed that the median data efficiency in deployed environments has been 40:1, with one-third of customers achieving data efficiencies of 100:1 or higher.
According to CIO, data protection is one of the biggest issues that IT faces today – an indicator of the growing need for robust backups and strong security. HPE SimpliVity provides built-in data protection with completely integrated local and remote backups at the VM level. There is a provision for remote backups to another site or to the cloud which happen in ten-minute RPO intervals. The Data Virtualization Platform also offers instant VM recoverability. Due to the Global Federated Architecture, a single administrator can manage all datacenters and branch offices located anywhere globally, and also grant the visibility and control to take action on individual VMs.
How HPE SimpliVity gives a competitive edge to enterprises
As the investment on operational expenses skyrockets and proves to be unsustainable, many organizations are reassessing their processes linked to procuring and managing datacenter assets. They are keen to cut down their dependence on inflexible silos of datacenter infrastructure and numerous specialists to handle the same. This is driving adoption of converged and hyperconverged infrastructures. Take a look at the multiple benefits that HPE SimpliVity offers to enterprises.
Speed: The hyperconverged building blocks can be quickly deployed and scaled as per the requirements. All datacenters and edge computing environments can be viewed on a single interface within your virtual environment.
Resiliency: Enterprises can mitigate data loss and security threats due to high levels of resiliency, disaster recovery (DR), and rapid backup offered by this powerful solution.
Simplicity and efficiency: HPE SimpliVity helps enterprises transform their VM environments, while delivering cloud-like speed and agility across all their private clouds. Apps can be deployed quickly and easily. VM environments can be managed with ease, which frees up 91% of IT staff’s time to spend on new projects, according to a recent IDG white paper.
Decisions made by IT departments are very important to the broader business today. IT departments must be prompt in their response to new business initiatives and models that are designed to generate bottom-line improvements and develop new revenue streams. HPE SimpliVity has become a top choice for enterprises because it delivers next-generation IT infrastructure that boosts application performance, allows for ease of scale and importantly, reduces costs.
To learn more about how HPE SimpliVity hyperconverged solutions can deliver speed, resiliency, simplicity, and efficiency to your datacenters, check out the Gorilla Guide to Hyperconverged infrastructure Implementation Strategies.
Terraform Provider for HPE OneSphere
In this article I will show you the basics of how HPE OneSphere Terraform provider can used to interact with the HPE Hybrid Cloud management Platform.
Why Terraform?
HashiCorp Terraform is a powerful infrastructure orchestration tool used to create, manage, and update infrastructure resources. These resources may be physical machines, VMs, network switches, containers, or others. Almost any infrastructure type can be represented as a resource in Terraform.
HashiCorp Terraform manages existing and popular service provider platforms, as well as custom in-house solutions. Service providers, such as those delivering IaaS, PaaS, or SaaS (e.g. HPE OneSphere) capabilities, are responsible for understanding the API interactions and exposing the appropriate resources.
HPE OneSphere Provider
HPE OneSphere is a software-as-a-service (SaaS) hybrid cloud management platform that helps you build clouds, deploy apps, and gain insights faster. Providers using HashiCorp Terraform are responsible for the lifecycle of a resource: create, read, update, delete. HPE OneSphere Provider enables operators to create and manage resources like users, projects, deployments, etc. Organizations now have access to compute, network, and many other resources critical to provisioning applications in both test & dev environments. Understand that the provider needs to be configured with the proper credentials before it can be used.
HPE OneSphere Provider in Action Example
To demonstrate the workflow of HPE OneSphere provider, I am going to deploy a simple infrastructure on the HPE OneSphere platform. My goal is to deploy a virtual machine in HPE OneSphere using the HPE OneSphere provider. The first step is to setup the HashiCorp Terraform environment.
Installing terraform-provider-onesphere with Go
- Install Go 1.11. For previous versions, you may have to set your $GOPATH manually, if you haven’t done it yet.
- Install Terraform 0.9.x or above from here and save it into /usr/local/bin/terraform folder (create it if it doesn’t exists)
- Download the code by issuing a go get command.#Download the source code for terraform-provider-onesphere#and build the needed binary, by saving it inside $GOPATH/bin$ go get -u github.com/HewlettPackard/terraform-provider-onesphere#Copy the binary to have it along the terraform binary$ mv $GOPATH/bin/terraform-provider-onesphere /usr/local/bin/terraform
HPE OneSphere Setup
Before you can start, you need to have an administrator account to access the HPE OneSphere portal and perform the required operations.
Terraform Deployment
An infrastructure managed by Terraform is defined in .tf files, which are written in HashiCorp Configuration Language (HCL) or JSON. HashiCorp Terraform supports variable interpolation based on different sources such as files, environment variables, other resources, and so on.
Create a new definition file called example.tf inside /usr/local/bin/terraform folder.
# example.tf file
# OneSphere Credentials
provider "onesphere" {
os_username = ONESPHERE_USERNAME
os_password = ONESPHERE_PASSWORD
os_endpoint = ONESPHERE_PORTAL_URL
os_sslverify = true
}Running terraform init will give the following output:

For now, I am going to use four basic commands: plan, apply, show, and destroy. Similar to the init command, these can be executed using the HashiCorp Terraform CLI (terraform command).
Steps
Add Project
First, I am going to create an HPE OneSphere project by including a resource configuration block “onesphere_project” in example.tf file.
#example.tf
# Create a new OneSphere Project
resource "onesphere_project" "terraform" {
name = "terraform"
description = "terraform project"
taguris = ["/rest/tags/environment=demonstration", "/rest/tags/line-of-business=incubation", "/rest/tags/tier=gold"]
}Running terraform plan tells me that it will create the new project called “terraform” once I apply the changes.

Other than the id field, there are no other fields from the pasted output. A computed field means that HashiCorp Terraform will produce a value once the plan is executed. You will see later how you can access those computed values directly rather than using terraform show.
I next execute terraform apply. It will first print the plan and ask for confirmation.

When I approve, the resources will be created in the correct order. HashiCorp Terraform parallelizes the creation of independent resources.

Add Network:
As the network is already present in HPE OneSphere, I first need to import the network to bring it under HashiCorp Terraform management. The current version of terraform import can only import resources into the state. It does not generate a configuration. A future version will also generate the configuration. Because of this, prior to running terraform import, it is necessary to manually write a resource configuration block for the resource to which the imported object will be mapped.
Here, I create an HPE OneSphere network resource configuration block to which the imported object will be mapped.
#example.tf
# Import a OneSphere Network
resource "onesphere_network" "terraformnetwork" {
}Now, I will execute terraform import –provider=onesphere onesphere_network.terraformnetwork <Id.> <Id.> is the network id.

The next step is to provide network access to the created project “Terraform” by performing “add” operation.
#example.tf
# Provide Network access to the Project
resource "onesphere_network" "projectnetwork" {
networkname = "VMDeployment171"
zonename = "synergy-vsan-deic"
operation = "add"
projectname = "terraform"
}
Running terraform plan will tell me that it will update the network called “terraformnetwork” once we apply the changes.

Once again, I execute terraform apply. Again, it will print the plan and ask for confirmation.

When I approve, the network access will be provided to the project.

Add Deployment
NOTE: The administrator needs to create a service group with services and expose it to the terraform project. Only those services can be deployed under the project.
Let’s assume that administrator exposed “rhel61forsca” service to the terraform project.
Now I create an HPE OneSphere deployment by including a resource configuration block “onesphere_deployment” in example.tf file.
#example.tf
# Create a new deployment
resource "onesphere_deployment" "terraform" {
name = "Terraform-Deployment"
zonename = "synergy-vsan-deic"
regionname = "emea-mougins-fr"
servicename = "rhel61forcsa"
projectname = "terraform"
virtualmachineprofileid = "2"
networkname = "VMDeployment171"
}Running terraform plan will tell me that it will create the new deployment called “Terraform-Deployment” once I apply the changes.

Once again, I must execute terraform apply. It will print the plan and ask for confirmation.

When I approve, the resources will be created in the correct order. Terraform parallelizes the creation of independent resources.

The goal to create a virtual machine using HPE OneSphere provider was successful.
Authentication
The HPE OneSphere provider supports static credentials and environment variables.
Next Steps
There are many ways to consume an API such as HPE OneSphere. HPE OneSphere provider is one option. In future articles, I will explore other approaches. I’ve posted a helpful HPE OneSphere interactive API guide here on our Developer Portal. Use this guide to learn which routes your application can use. And if you’re already an HPE OneSphere customer, simply use the https://my-instance-name.hpeonesphere.com/docs/api/ URL to see your own fully interactive API guide.
How VM data is managed within an HPE SimpliVity cluster, Part 4: Automatic capacity management
This blog is the fourth in a 5-part series on VM data storage and management within HPE SimpliVity powered by Intel®.
The customers I talk to find HPE SimpliVity hyperconverged infrastructure extremely simple to use. They are savvy enough to know that that’s because there’s a lot going on behind the scenes, and they are technical enough to be curious about how it all works. Discovering the architectural ins and outs, and learning how data in a virtual machine is stored and managed in an HPE SimpliVity cluster can lead you to a better understanding of how data is consumed in your specific HPE SimpliVity environment, and how you can best manage it.

If you have been following this blog series, you know that I’m exploring HPE SimpliVity architecture at a detailed level, to help IT administrators understand VM data storage and management in HPE hyperconverged clusters.
Part 1 covered virtual machine storage and management in an HPE SimpliVity Cluster. Part 2 covered the Intelligent Workload Optimizer (IWO) and how it automatically manages VM data in different scenarios. Part 3 followed on, outlining options available for provisioning VMs.
Now in Part 4, I will cover how the HPE SimpliVity platform automatically manages virtual machines and their associated data containers after initial provisioning, as the VMs grow (or shrink) in size.
Note: The hyperconverged architecture is comparable in either VMware vCenter or Microsoft Hyper-V environments. For simplicity’s sake, I will focus on VMware environments in this post.
HPE SimpliVity Auto Balancer Service
The HPE SimpliVity Auto Balancer service is separate from IWO and the Resource Balancer service; however, its goal is the same: to keep resources as balanced as possible within the cluster.
Together, IWO and the Resource Balancer service are responsible for the provisioning of workloads (VM and associated data container placement). The Auto Balancer service is responsible for management of these data containers as they evolve in regards to overall node consumption (and cluster) consumption.
As I explained in Part 2 of this series, IWO keeps the VMware Distributed Resource Scheduler (DRS) aware of data location to help boost performance. IWO is aware of any changes that Auto Balancer carries out and will update VMware DRS affinity rules accordingly, should one or more data containers be relocated due to a node becoming space constrained.
How does it work?
The Auto Balancer service automatically migrates secondary data containers for any VM (except for VDI VMs) and associated backups to less utilized nodes should a node be running low on available physical capacity.
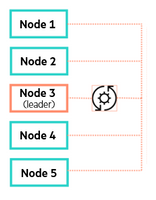
The Auto Balancer service runs on each node. One node in a cluster is chosen as a leader.
The leader may change over time or as nodes are added/removed from the cluster.
The Auto Balancer leader will submit tasks to other nodes to perform data container or backup migrations.
When will it operate?
The Auto Balancer service will not operate until a node is at least 50% utilized (in terms of capacity). As with IWO and the Resource Balancer service, Auto Balancer is also designed to be zero touch, i.e. the process is handled automatically. Remember, as previously covered, the Resource Balancer service handles the initial placement when the data container is created, the Auto Balancer handles the migration of these data containers if a node becomes space constrained.
A decrease in physical capacity on a node can be a result of the growth of one or more VMs, backups or the provisioning of more virtual machines into an HPE SimpliVity cluster.
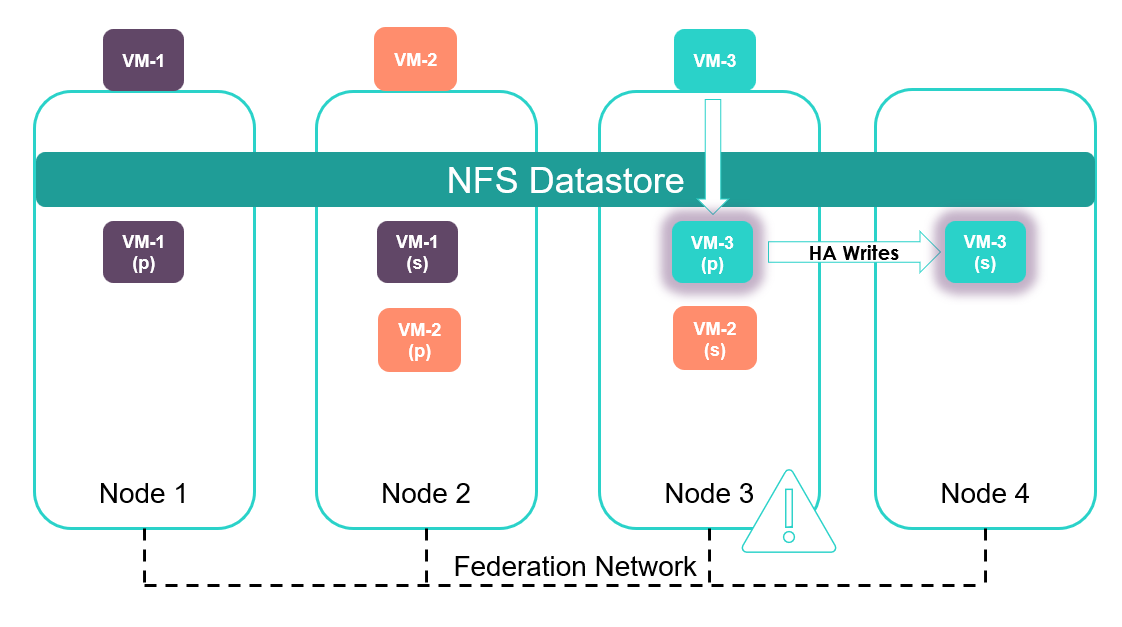
In the below illustration, VM-3’s on-disk data has grown by an amount that has caused Node 3 to become space constrained. The Auto Balancer service will now take a proactive decision to rebalance data across the cluster to try and achieve optimum distribution of data in terms of capacity and IOPS.Node 3 is full. As a result, Auto Balancer moves one or more data containers to balance the cluster.
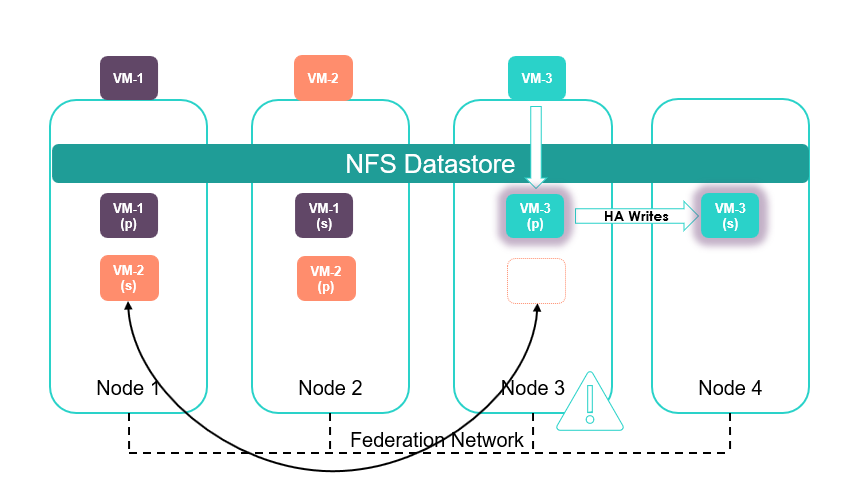
In this example, Auto Balancer has elected to migrate VM-2’s secondary (standby) data container and its associated backups to Node 1. This process is handled automatically.The Auto Balancer service may or may not migrate the data containers that have grown.
The above illustration does not scale well when representing multiple nodes and virtual machines. It is easier to represent virtual machines and nodes in table format below; this format will also prove useful in the next post when I will share how to view data distribution across nodes for individual VMs and backups and how to manually balance this data if required.

Here is a second example to reinforce the lessons from the previous posts in regards to DRS, IWO and automatic balancing of resources.
For the sake of simplicity, the total physical capacity available to each node in the above table is 2TB. The physical OS space consumed after deduplication and compression for each VM is listed. For this example, backup consumption is omitted. Therefore, the cluster is relatively balanced with no nodes space constrained. Here is an overview:
- Total cluster capacity is 8TB (2TB x 4)
- Total consumed cluster capacity is 2.1TB ((50 + 300 + 400 + 300) x 2)
- Node 3 is currently the most utilized node, consuming 1TB of space
- DRS has chosen not to run any primary workload on Node 4
Now, imagine consumed space in Node 3 grows by 200GB and CPU and memory consumption also increases. The cluster is no longer balanced:
- Total cluster capacity remains at 8TB
- Total consumed cluster capacity is 2.5TB (50 + 300 + 600 + 300)
- Node 3 is currently over-utilized, consuming 1.2TB of space.
- An automatic redistribution of resources may move data such that it matches the table below.
DRS has chosen to run VM-4 on Node 4 due constrained CPU and Memory on Node 3, thus promoting VM-4’s standby data container to the primary data container.

The Auto Balancer service has migrated the secondary copy of VM-3 to Node 1 to rebalance cluster resources.
It is worth noting that other scenarios are equally valid, i.e., VM-4 secondary data container could also have been migrated to Node 1 for example (after the DRS move), which would have resulted in roughly the same redistribution of data.
Viewing the status of auto balancer
The command “dsv-balance-show –shownodeIP“ command shows the current cluster leader.
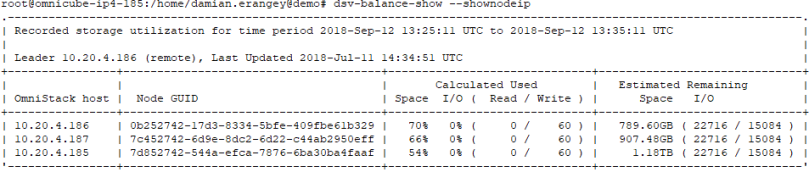
Here the current leader is OVC 10.20.4.186
The log file balancerstatus.txt shows submitted tasks and status on the leader node. In other words, this txt file is only visible from the leader node.
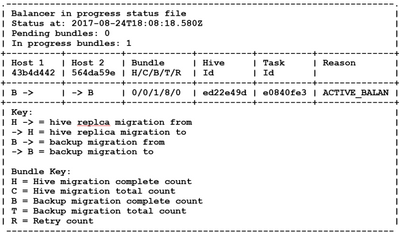
Issue the command “cat /var/svtfs/0/log/balancerstatus.txt” to view the status of any active migrations.The output of this file shows the migration of backup from Node 1 to Node 2.
Another handy command is ‘dsv-balance-migration-show – showVMName’ which was introduced in version 3.7.7. This is cluster wide command so it can be run from any node in the cluster. This will list the Virtual Machine being migrated along with the host it has been migrated from and too.
Note: Currently the Auto Balancer does not support the migration of remote backups.
Closing thoughts
The HPE SimpliVity Intelligent Workload Optimizer (IWO) and Auto Balancer features balance existing resources, but cannot create resources in an overloaded cluster. In some scenarios, manual balancing may be required. The next post will explore some of these scenarios, how to analyze resource utilization and manually balance resources within a cluster if required.
More information about the HPE SimpliVity hyperconverged platform is available online:
- HPE SimpliVity Data Virtualization Platform provides a high level overview of the architecture
- You’ll find a detailed description of HPE SimpliVity features such as IWO in this technical whitepaper: HPE SimpliVity Hyperconverged Infrastructure for VMware vSphere